Adding schema.org metadata to Jekyll
How to ensure that Google+ extracts snippets from your blog posts
How Google+ generates snippets
I recently decided to migrate my Blogger blog to Jekyll, using Jekyll Now as a starting point. I soon realized that Google+ no longer extracted snippets from links to posts I wanted to share:
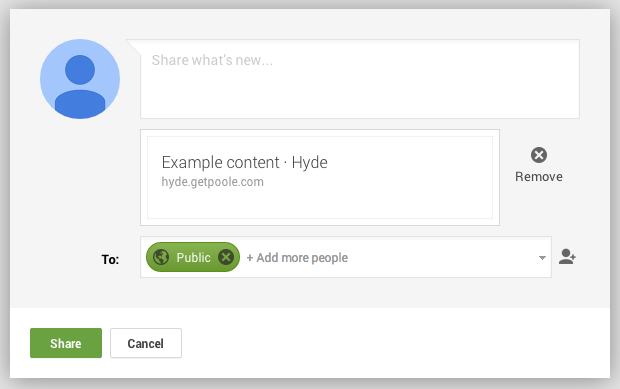
As can be seen in this screenshot, Google+ only shows the title and the Web site, but no snippets for posts generated with the kind of Jekyll layout I was using. While researching why this happens, I found the following document that explains how Google produces snippets for pages shared via Google+:
https://developers.google.com/+/web/snippet/
According to that document the recommended way to enable snippets is to annotate the page with schema.org microdata.
Annotating your blog posts
For a blog post the appropriate item type
is http://schema.org/BlogPosting (which inherits from
http://schema.org/Article).
Google+ uses the name property to extract the title and the description property to generate
the snippet, but while we are at it, we may as well use some additional properties such as
keywords and datePublished to annotate information that is available in Jekyll anyway.
Although the snippet extraction actually works if the entire body of the post is annotated as description,
that would obviously be a misuse of the http://schema.org/BlogPosting schema.
A more accurate way is to annotate the body with articleBody and to produce the description property
using the strip_html and truncatewords (or truncate) filters provided by the Liquid Templating language.
A blog post layout may then look like this:
<article class="post" itemscope="" itemtype="http://schema.org/BlogPosting">
<meta itemprop="keywords" content="{{ page.tags | join: ',' }}" />
<meta itemprop="description"
content="{{ content | strip_html | truncatewords: 40 }}" />
<h1 itemprop="name">{{ page.title }}</h1>
<ul class="taglist">
{% for tag in page.tags %}
<li class="tag">{{ tag }}</li>
{% endfor %}
</ul>
<time class="published" itemprop="datePublished"
datetime="{{ page.date | date: '%Y-%m-%d' }}">
{{ page.date | date: "%B %e, %Y" }}
</time>
<div class="entry" itemprop="articleBody">
{{ content }}
</div>
</article>
The schema.org microdata is provided by the itemscope, itemtype and itemprop attributes.
Also notice the usage of <meta> tags for properties the values of which don’t appear literally on the rendered page.
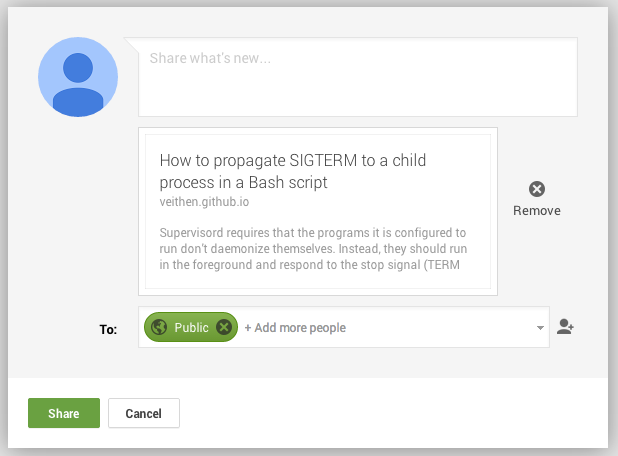
With this layout, Google+ will now generate the kind of snippets we would expect:
Checking the metadata
If you want to check the correctness of the metadata on your pages, you can use the following online tool provided by Google:
http://www.google.com/webmasters/tools/richsnippets
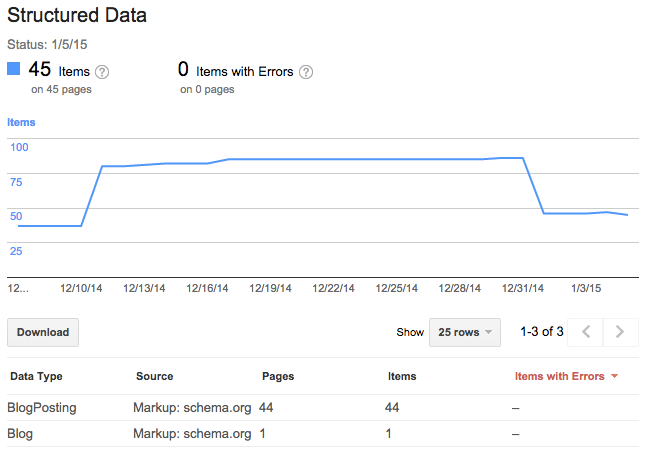
If your site is registered with Google’s Webmaster Tools, you can also check the extracted metadata for your site under Search Appearance > Structured Data, but you will have to wait until the Web crawler has processed the pages (which may take a few days):
Images
Even for a blog post annotated as described above, Google+ may still refuse to extract a snippet. The reason for this is the following requirement:
In addition to the required schema markup, the image [for the blog post] must be sized as follows:
must be at least 400px wide.
must have an aspect ratio no wider than 5:2 (width:height).
The image for a blog post is set using the image property. If that property is not specified, Google+ will
attempt to extract an image from the content of the post. There are three possible situations:
-
The post doesn’t contain any images at all. In this case, Google+ generates a snippet with a description and without image.
-
Google+ extracts an image from the post that satisfies the requirements described above. In this case, Google+ generates a snippet with a full-bleed image and a description.
-
The images in the post don’t meet the requirements, i.e. are too small or have the wrong aspect ratio. In this case, no snippet is generated.
One possible solution for this problem is to add an image property to all posts and let it point
to a suitable image that serves as the logo for your blog.
Adding metadata to your blog’s home page
Annotating blog posts with http://schema.org/BlogPosting metadata enables correct snippet extraction in Google+. If you want semantically complete metadata for your site, then you may also want to declare the home page of your blog as a http://schema.org/Blog item and link that to your blog posts:
<div class="posts" itemscope="" itemtype="http://schema.org/Blog">
<h1 itemprop="name">My blog</h1>
{% for post in site.posts %}
<article class="post" itemprop="blogPost" itemscope="" itemtype="http://schema.org/BlogPosting">
<h2><a href="{{ post.url }}" itemprop="url"><span itemprop="name">{{ post.title }}</span></a></h2>
<meta itemprop="keywords" content="{{ post.tags | join: ',' }}" />
<div class="entry" itemprop="description">
{{ post.content | strip_html | truncatewords: 40 }}
</div>
</article>
{% endfor %}
</div>
Notice how the following two properties are used to create a relationship between the blog and individual posts it contains:
-
blogPost: a collection of http://schema.org/BlogPosting items. -
url: links each http://schema.org/BlogPosting item in theblogPostcollection to the actual page containing the full item (i.e. the http://schema.org/BlogPosting item with the complete set of metadata properties).
What about Facebook and Twitter?
Unfortunately Facebook and Twitter don’t use schema.org metadata to produce rich snippets. Facebook relies on
Open Graph meta tags, which need to be added
to the header of the HTML page. Twitter defines its own set of meta tags,
but supports Open Graph as fallback. This means that if you already have added the Open Graph metadata, then only the
twitter:card tag is required to support Twitter.